[Papers] Multiply: Reconstruction of Multiple People from Monocular Video in the Wild (CVPR 2024)
MultiPly: Reconstruction of Multiple People from Monocular Video in the Wild
[Paper] [Github] [Demo]
Title: MultiPly: Reconstruction of Multiple People from Monocular Video in the Wild
Journal name & Publication year: CVPR 2024
First and Last Authors: Jiang, Zeren
First Affiliations: ETH Z ̈urich
Abstract & Introduction
Limitation 기존 3D Shape estimating과 3D Reconstruction 분야는 빠르게 발전해왔지만 monocular(단일 카메라) video에서 인물들간의 interaction이 있을 때 즉, occlusion이 있을 때 잘못된 예측과 생성을 하는 한계점들이 존재하였다.
Expected Outcomes 만약 이를 통해 해결이 되고 더욱 발전이 된 Model과 방법론들이 등장한다면 장비가 비싼 Virtual이나 증강, 가상현실 산업에서 카메라 하나를 가지고 인물을 온전히 Reconsturction 할 수 있는 AI 기술도 나올 수 있지 않을까 싶다.
결론적으로 MultiPly는 위의 multi-person reconstruction의 limitation을 해결하고 3D, AR, XR, 4D등 다양한 산업에서도 사용할 수 있는 방법론을 제시한다.

Method 1: Layered Neural Representation
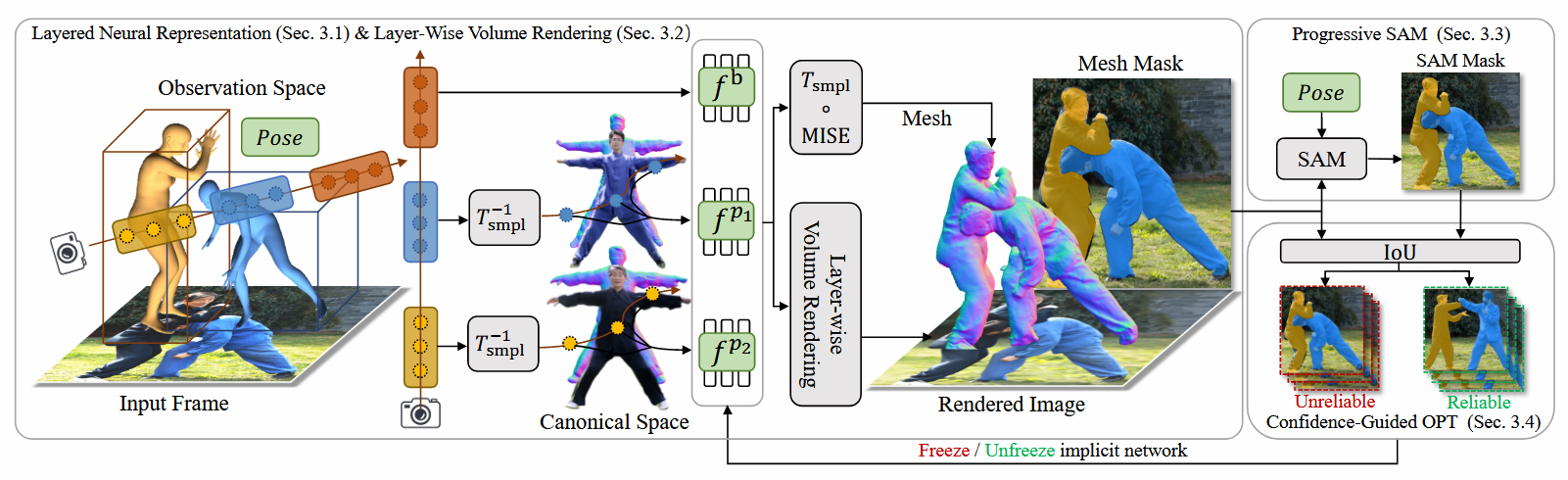
Neural Avatars.
기본적으로 3D Reconstruction을 위해 인물을 표현하는 3D shape 정보와 인물의 외관을 표현하기 위한 Appearance 정보가 필요하게 된다.
Implicit Representation 지속적으로 나오는 Implicit Representation이라는 표현은 단순히 3D 형태로 표현하기 위한 mesh나 point cloud가 아닌 수학적 표현으로 함축하겠다는 것을 의미하게 된다. 이는 계산과 자원의 효율성을 충족하기 위해서 사용한다고 봐야할 것이다.
3D Shape 먼저 3D shape의 기하학적인 구조를 표현하기 위해 signed-distance field(SDF) 를 사용하게 된다. SDF는 3D 공간의 각 점에 대해 표면까지의 거리와 방향을 계산해 저장하는 함수이다. 이를 통해 3D shape정보를 mesh나 point cloud 없이 컴팩트하게 저장할 수 있게 된다.
Signed Distance Field (SDF) SDF는 3D 공간 내의 각 점에서 특정 표면까지의 부호 있는 거리(signed distance) 를 정의하는 스칼라 필드이다. 이 값은 기하학적 정보를 컴팩트하게 표현할 수 있어 다양한 3D 표현 방식에서 사용된다.
SDF의 구성 원리
정의: SDF(p)는 3D 공간의 점 p에서 특정 표면까지의 최소 유클리드 거리와 부호를 반환하는 함수입니다.
- 양수 값 (+): 점이 표면의 외부에 위치함을 의미.
- 음수 값 (-): 점이 표면의 내부에 위치함을 의미.
- 값이 0일 때: 점이 표면 위에 정확히 위치함을 의미.
Appearance 다음으로 인물의 외관 Appearance을 Texture Field로 표현한다. 이는 특정 점에서의 색상이나 방사량(빛의 강도)을 표현하는 함수로 사람의 외형(옷, 피부색)을 나타낼 수 있게 된다. SDF로 출력된 값들 중 값이 0인 것들은 물체의 표면을 의미하기 때문에 이에 집중하여 3D 좌표와 SDF값에 따라서 $c^p$(RGB, 광학 방사량)을 계산하게 되는 것이다.
Layerd Representation 해당 논문에서는 multiple people들을 분리하여 3D Representation하는 것이 목표이므로 이를 위해 Layer를 기반으로 각 인물에 대한 정보들을 표현하며 최종적으로 모든 계층을 종합하여 구성하는 방식을 따르고 있다. 결론적으로 하나의 모델로 학습을 하지만 독립적인 계층으로 분리하여 각 인물들의 정보를 표현한다는 것이다.
최종적으로 수식적으로 살펴보면 사람 $p$를 표현하기 위한 신경망 $f^p$로 표현이된다. \(c^p, s^p = f^p(x_c^p, \theta^p)\)
$f^p$: 사람 p를 표현하는 신경망 $x_c^p$: 특정 점의 좌표 $\theta^p$: 인물의 pose paramter $c^p$: texture field 정보 $s^p$: SDF 정보
Deformation Module.
현재 우리가 표현하는 canonical space의 해당하는 $x_c^p$좌표들은 인물의 포즈 정보가 담겨있지 않은 T-Pose의 정보로 구성되어있다. 이를 포즈 정보를 포함한 Deformed space의 $x_c^p$로 표현하기 위해 대중적으로 사용하는 SMPL을 사용한다. 추가적으로 자연스러운 skin 표현을 위해 LBS도 사용한다고 한다.
반대로 T-Pose를 표현하기 위해 $x_d^p$와 $\theta^p$를 SMPL의 역함수를 이용하여 $x_c^p$로 표현할 수도 있다고 한다.
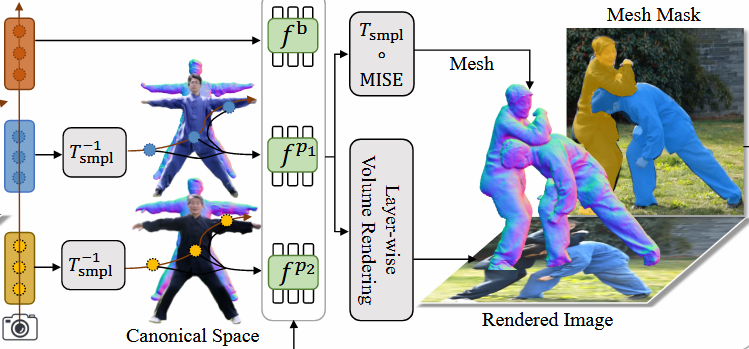
Method 2: Layer-Wise Volume Rendering
해당 부분은 Layer별 인물들을 Volume Rendering 하기 위한 방법들을 설명한다.
Volume Rendering for Human Layers.
기존의 Vanila Volume Rendering과 조금 다르게 dynamic한 장면들과 인물별로 layered된 표현을 Volume Rendering하고 싶어하는 것이 목표이며 차이점이다.
opacity & density
먼저 Volume Rendering을 위한 각 점에 대한 opacity와 density를 구하게 된다. 밀도 $\sigma$는 deformed 좌표와 SMPL의 역함수를 이용한 값에 Laplace distribution’s Cumulative Distribution Function(CDF)를 이용하여 계산하고 해당 밀도를 이용하여 sampling된 점들의 좌표값 차이와 함께 해당 sampling의 opacity값을 계산하게 된다.
Radiance Accumulation
위에서 구한 opacity값과 color값을 이용하여 인물별 Volume Rendering을 진행하게 된다.
핵심적으로 multi-people에서의 Volume Rendering 문제를 해결하기 위해 $Z_i^{q,p}$를 이용하여 샘플 i점보다 앞에 있는 점들의 집합을 이용하여 가려지는(occlusion)문제를 해결했다고 한다.
\[\hat{C}_H = \sum_{i=1}^N \sum_{p=1}^P \left[o_i^p c_i^p \prod_{q=1}^P \prod_{j \in Z_i^{q,p}} \left( 1 - o_j^q \right) \right]\] \[Z_i^{q,p} = \{j \in [1, N] \mid z(x_{d,j}^q) < z(x_{d,i}^p) \}\]Scene Composition
위에서 구한 인물에 대한 Volume Rendering Color값 $\hat C_H$값과 NeRF++에서 사용되는 Background Color값 구하는 $f^b$를 이용하여 나온 $\hat C^b$을 Composition 하여 최종 Color값 $\hat C$를 계산하게 된다.
Method 3: Progressive Prompt for SAM
SAM을 이용하여 더 정확한 instance segmentation mask를 업데이트하고 생성하는 방법론들을 설명한다.
아직도 occlusion에 대한 문제가 있기 때문에 이를 해결하기 위해 promptable segmentation model인 SAM을 이용하여 더 정확한 인물별 instance segmentation이 가능하게 된다.
Deformed Mesh
SDF에서 매쉬를 효율적으로 추출할 수 있는 Multiresolution IsoSurface Extraction(MISE) 알고리즘을 이용하여 해당 p에 대한 mesh 값들을 구하게 된다.
Instance Mask
이후 변형된 mesh를 differentiable rasterizer $R$을 이용하여 instance mask $\mathcal{M}$을 만들어준다. $\mathcal{M}$ = 1 : 메쉬 내부 영역 $\mathcal{M}$ = 0 : 메쉬 외부 또는 가려진 영역
Point Prompt
추가적으로 SAM에 전달할 point prompt를 2D keypoint기반으로 생성한다. 해당 값들은 SMPL을 통해 나온 파라미터들로 구할 수 있다.
Progressive Update
위에서 구한 prompt들을 이용하여 instance mask $\mathcal{M}$을 지속적으로 업데이트하여 보다 정확한 segmentation 정보를 얻게 된다.
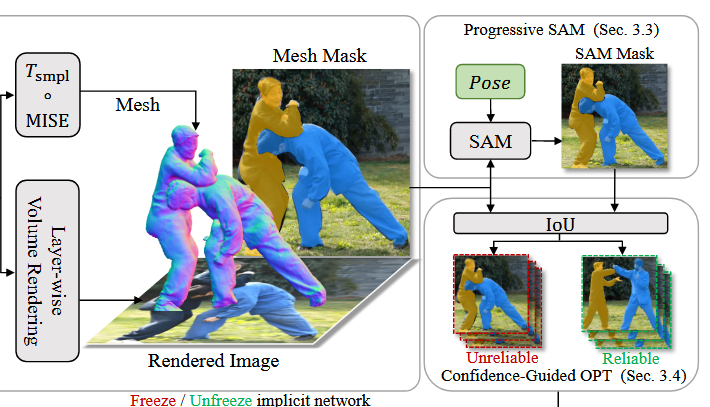
Method 4: Confidence-Guided Alternating Optimization
인물간의 가려짐으로 인한 부정확한 pose나 잘못된 depth를 예측하는 경우가 생기게 된다. 기존의 pose와 shape을 동시에 optimize하는 것보다 좋은 방법으로 pose와 shape을 번갈아 최적화하는 confidence-guided optimization(신뢰도 기반 최적화)을 제시한다.
Confidence-Guided Optimization
mesh기반 mask $\mathcal{M}{\text mesh}^{p,i}$ 와 SAM을 통해 정제된 $\mathcal{M}{\text sam}^{p,i}$ 를 통해 IoU 계산을 함으로써 해당 mask에 대한 신뢰도를 측정한다.
한 frame의 scene에 있는 mask에 대해 모두 계산한 IoU의 평균값이 $\alpha (\text{threshold})$ 이상일 경우 해당 frame을 reliable한 frame이라고 정의한다.
\[\mathcal{L}_r = \{ I_i \in \mathcal{L} \mid \frac{1}{P} \sum_{p=1}^P \text{IoU}(M_{\text mesh}^{p,i}, M_{sam}^{p,i}) \geq \alpha \},\]Alternating Optimization
“To avoid damaging shape updates that are due to wrong poses, we only optimize pose parameters for unreliable frames and jointly optimize pose and shape parameters for reliable frames.”
위의 표현에서 볼 수 있듯이 wrong poses로 인해 shape이 손상되지 않도록 unreliable frame에서는 pose만, reliable frame에서는 pose와 shape을 동시에 optimization하는 방법을 제안한다.
Method 5: Objectives
Reconstruction Loss.
예측된 Color와 GT의 Color의 $L_1-\text{distance}$ 값으로 Loss를 구성한다. $\mathcal{R}$은 샘플링된 ray를 의미한다.
\[L_{rgb} = \frac{1}{\left|\mathcal{R}\right|} \sum_{r \in \mathcal{R}} \left| C(r) - \hat {C}(r) \right|\]Instance Mask Loss.
Volume Rendering에서 사용하는 opacity $o^p$ 값을 최적화 하는 Loss이다.
\[\hat{O}^p(r) = \sum_{i=1}^N \left[ o_i^p \prod_{q=1}^P \prod_{j \in Z_i^{q,p}} (1 - o_j^q) \right].\]아래는 sam의 refined mask와 인물 $p$에 대한 투명도 값의 $L_1-\text{distance}$를 계산한다. mask와 mask가 아닌것이 의아했지만, 생각해보면 두 값 모두 해당 pixel에 해당 인물이 있냐 없냐를 표현한다는 동일한 목표를 가지고 있기 때문에 충분히 계산이 가능하고 최적화가 가능한 부분이다.
\[L_{\text{mask}} = \frac{1}{|\mathcal{R}|} \sum_{r \in \mathcal{R}} \sum_{p=1}^P \left| \mathcal{M}_{\text{sam}}^p(r) - \hat{O}^p(r) \right|.\]Eikonal Loss.
SDF 함수의 gradient 값을 1로 제약을 두는 loss를 구성한다. 만약 gradient 크기가 1을 유지하지 못하면 SDF의 성질을 갖지 못하는 것이므로 신뢰하기 어렵게 된다.
\[L_e = \sum_{p=1}^P \mathbb{E}_{x_c} \left( \left\| \nabla f_s^p(x_c^p, \theta^p) \right\| - 1 \right)^2.\]Depth Order Loss.
결국 3D Reconstruction이기 때문에 중요한 depth order에 대한 loss를 구현한다.
\[L_\text{depth} = \sum_{(u,p,q) \in \mathcal{D}} log(1+exp(D_p(u)-D_q(u))),\]Interpenetration Loss.
해당 Loss는 물리적으로 불가능한 사람들의 겹치는 현상을 방지하기 위해 쓰이는 Loss이다. mesh기반의 3D 분야에서 많이 보이는 문제로 한 사람의 팔이 다른 사람의 팔을 침투하는 것이 예시가 된다.
이는 복잡한 다중 사람 장면에서 메쉬 복원의 정확도를 높이고, 물리적으로 타당한 결과를 생성하는 데 도움을 준다.
\[L_\text{inter} = \sum_{p=1}^{P} \sum_{q=1,q\neq p}^{P} \left|| \mathcal{V}_{in}^{p,q} - NN(\mathcal{V}_{in}^{p,q},S_d^q) \right||\]Experiments
보다 높은 성능을 보여주기 위해 사용된 방법론들이 추가적으로 많은 디테일들을 끌어 올려주는 것을 확인할 수 있다.
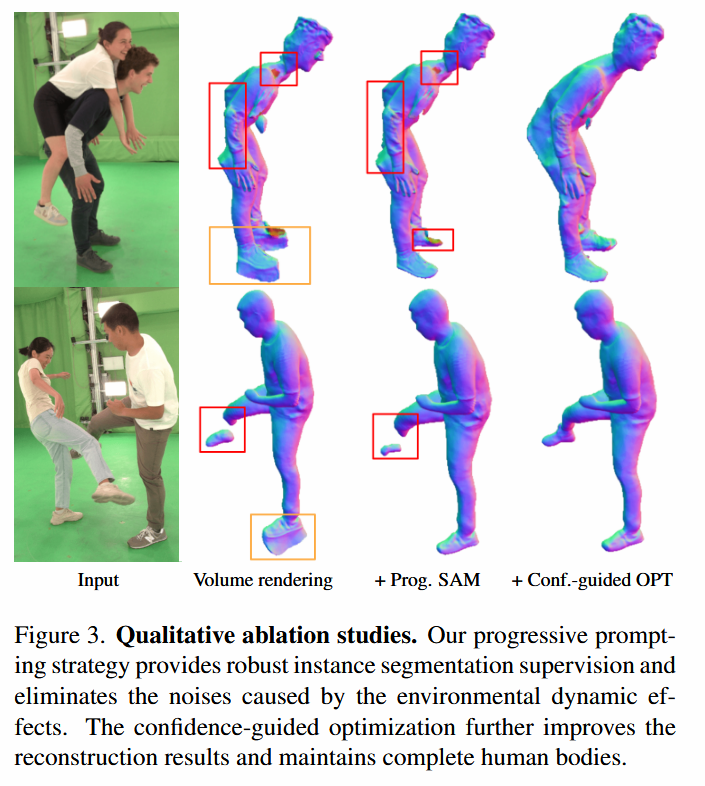
multi-people Reconstruction에서 겹침이 있음에도 인물간의 복원과 분리가 완벽히 되는 것을 확실하게 보여주는 사진이다.

Reference.
https://arxiv.org/abs/2406.01595 https://github.com/eth-ait/MultiPly https://eth-ait.github.io/MultiPly/ https://www.youtube.com/watch?v=r9giQPUp1Gw
Enjoy Reading This Article?
Here are some more articles you might like to read next: