[Papers] VITON: An Image-based Virtual Try-on Network (IEEE 2018)
VITON: An Image-based Virtual Try-on Network (IEEE 2018)
[Paper] [Github] [Demo]
Title: VITON: An Image-based Virtual Try-on Network
Journal name & Publication year: Not specified, Arxiv preprint in 2018
First and Last Authors: Xintong Han, Larry S. Davis
First Affiliations: University of Maryland, College Park
평소 관심있었던 분야이기도 했고 현업에서 상업적으로 다양하게 이미 사용되고 있다는 것도 느꼈었기 때문에 Virtual Try-on이라는 분야에 관심을 가지게 되었다. 해당 논문은 Virtual Try-on 분야의 초기 논문이다.
Abstract & Introduction & Related Work
지속적으로 수요가 급증하고 있는 온라인 쇼핑 산업에서 점점 더욱 더 간편하게 쉽게 소비를 할 수 있는 환경으로 발전하고 있는 요즘이다. 동시에 소비자들은 의류의 기재된 사이즈나 정보보다 실제 나에게 fit한 느낌을 알고 싶어하고 이것은 결국 불안한 소비로 이어지게 된다. 이를 해결하기 위해 제시하는 VITON은 아이템을 구매하기 전 아이템을 가상으로 착용해보며 소비자는 가상의 쇼핑 경험을 하고, 소매업체는 서비스 비용 절감을 할 수 있게 된다. 
해당 논문에서는 현실적인 제약이 많고 cost가 높은 3D 정보를 전혀 사용하지 않고 2D RGB 이미지 기반에 의존하는 VITON 모델을 제시한다. VITON 모델은 의류 제품 이미지를 사람의 해당 부위에 자연스럽게 합성되어 Photorealistic한 이미지를 생성하는데 목표를 두고 있다. 해당 목표를 위해서 생성된 이미지는 다음의 조건을 충족해야 한다고 한다.
- 1. 사람의 신체 부위와 자세가 원본 이미지와 동일해야 한다.
- 2. 목표 의류 아이템은 사람의 자세와 신체 형태에 따라 자연스럽게 변형되어야 한다.
- 3. 원하는 제품의 세부적인 시각적 패턴(색감, 질감, 디테일 등등)이 명확히 드러나야 한다.
위의 조건을 충족하기 위해서는 3D 정보를 활용 하더라도 힘들 것 같은데 2D 이미지로만 구현한다는 부분에서 큰 도전과제인 것 같다.
기존의 Virtual Try-on에 주로 사용되는 GAN에서는 목표 의류 아이템의 시각적 디테일을 모두 표현하지 못하고 기하학적 변화에 대한 결과가 좋지 않았는데 이러한 한계점을 해결하기 위해 VITON은 clothing-agnostic representation등 다양한 알고리즘들을 사용한다.
VITON
아래의 Model Architecture를 보았을 때 VITON은 큰 구조로는 두 개의 Network를 가지게 된다. 두 Network는 위에서 제시한 모델의 조건인 1,2번을 목표로 하는 Multi-task Encoder-decoder Generator가 있고 이를 통해 1,3번을 해결하기 위한 Refinement Network로 나뉘게 된다.
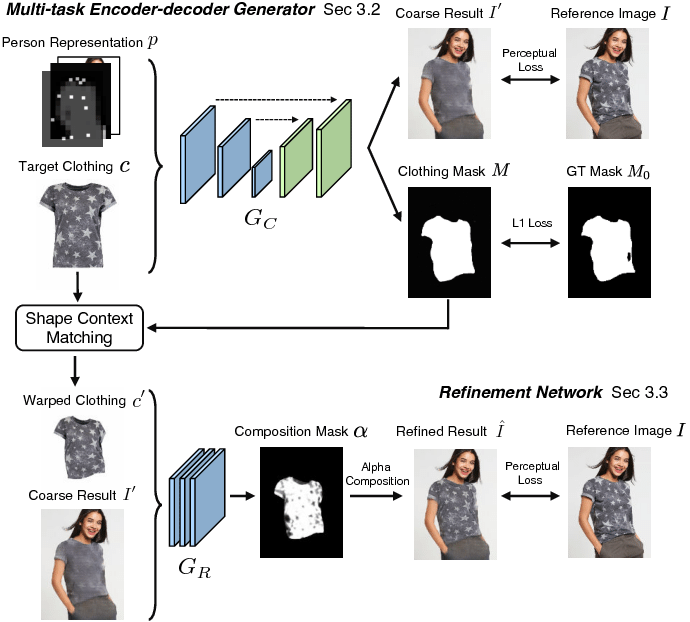
1. Person Representation
VITON의 가장 큰 challenge는 1번과 2번을 충족하는 부분이다. 3D 데이터일 경우 (x,y,z)의 point값과 같은 디테일한 정보를 통해 더욱 realistic한 표현이 가능하겠지만 2D Data만으로는 어려운 표현의 한계가 있기 때문이다. 이를 해결하기 위해 Peron Representation이라는 개념을 제시한다. 
- Pose heatmap. Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields (CVPR 2017) 먼저 제시된 의류를 인물 I에 맞추기 위해 pose estimation이 필요한데 이는 위의 논문에서 제시하는 model을 사용한다고 한다. 해당 모델을 사용하면 인물의 pose를 설명할 수 있는 주요 18개의 key-point가 11x11의 heatmap으로 제공되어 결론적으로 (18,11,11)의 정보값을 반환하게 된다.
18개의 정확한 위치 정보뿐만이 아니라 주변의 공간적 관계를 나타내는 11x11 heatmap을 통해 2D Image지만으로 표현하는데 한계였었던 공간적인 정보를 제공한다.
-
Human body representation. Look into Person: Self-supervised Structure-sensitive Learning and A New Benchmark for Human Parsing (CVPR 2017) 위에서 pose를 계산했다면 해당 pose에 의류가 fit하게 맞아야 한다. 이를 위해서 인물의 몸이 있는 위치 정보를 얻어내기 위해 위 논문에서 제시하는 human parser model을 사용한다. 이를 통해 1-channel로 구성된 binary mask를 얻고 의류가 충돌하는 등의 artifacts를 피하기 위해 (16x12)로 의도적으로 downsampling을 한다고 한다.
-
Face and hair segment. Look into Person: Self-supervised Structure-sensitive Learning and A New Benchmark for Human Parsing (CVPR 2017) 마지막으로 인물의 식별을 위해서 해당 인물이라고 표현할 수 있는 human parser를 위해 위에서 사용했던 모델을 사용하여 인물의 Face and hair RGB이미지를 구한다.
왜 해당 인물이라고 표현하는 정보를 필요로 할까? 조금 찾아보니 이전의 모델들에서는 합성된 이미지에서 인물의 옷만 바뀌어야 하는데 인물의 얼굴, 머리카락 등 인물의 특징들이 변하는 문제가 있었다고 한다. 아마 이를 방지하기 위해 따로 구해놓는게 아닐까 싶다.
위의 세개의 정보를 결합하여 Person Representation을 의미하는 $p$를 만든다. $p \in \mathbb{R}^{m \times n \times k}$ 를 따르고 featuremap의 높이와 너비를 나타내는 m = 256, n = 192, 위에서 구한 정보들을 channel로 두어 18 + 1 + 3 = 22로 $p$는 $(256,192, 22)$의 shape을 가진다.
해당 $p$는 인물에 대한 풍부한 정보를 담고있어 보다 정교한 작업이 가능해진다.
2. Multi-task Encoder-Decoder Generator
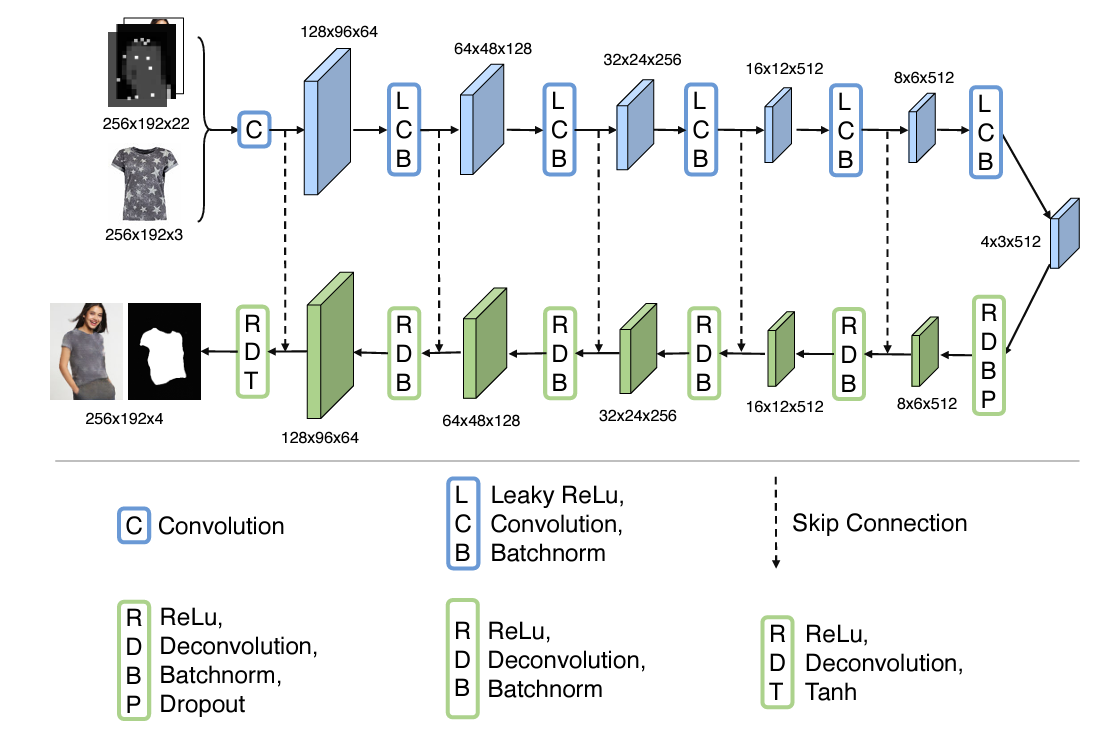 U-Net 구조로 이루어진 Encoder-Decoder Generator Network에서는 입력으로 주어지는 인물 정보 p와 의류 c를 통해 c가 p의 영역으로 자연스럽게 합성되는 것을 목표로 한다. 또한 뒤의 Refinement Network에서 사용될 clothing mask도 같이 추출하게 된다.
U-Net 구조로 이루어진 Encoder-Decoder Generator Network에서는 입력으로 주어지는 인물 정보 p와 의류 c를 통해 c가 p의 영역으로 자연스럽게 합성되는 것을 목표로 한다. 또한 뒤의 Refinement Network에서 사용될 clothing mask도 같이 추출하게 된다.
해당 model의 출력을 근사된 함수로 표현하면 4-channel로 구성된 $G_c(c,p) = (I’,M)$으로 표현되고 앞에 3개의 channel에는 합성된 이미지 $I’$을 의미하고 마지막 channel에는 clothing mask인 $M$을 의미한다. 인물이 보았을 때 이질감이 없이 realistic한 결과물을 위해서는 L1 loss가 아닌 인간의 실제 관측한 값과 가깝게 학습하기 위해 perceptual loss를 이용한다. ($M_0$는 human parser에서 예측한 psuedo ground truth clothing mask) 더 자세하게는 coarse image와 Ground truth의 feature map에서의 차이를 줄이기 위해 사용한다.
\[L_{G_c} = \sum_{i=0}^{5} \lambda_i \left\| \phi_i(I') - \phi_i(I) \right\|_1 + \left\| M - M_0 \right\|_1,\]수식에서 $\phi_i$는 VGG19 Network에 ImageNet이 사전학습된 모델로 순서대로 ‘conv1_2’, ‘conv2_2’, ‘conv3_2’, ‘conv4_2’, ‘conv5_2’로 각 layer에 feature map을 이용하여 feature map에서의 차이를 줄이는 방향으로 학습이 된다. 다만 i = 0일 경우 RGB 픽셀값의 차이인 L1 loss를 사용한다고 한다.
해당 perceptual loss를 최소화하는 학습을 반복함으로써 의상을 인물에 합성하게 되고 의류의 mask도 얻어내게 된다. 하지만 조건의 3번인 의류의 디테일을 표현하지 못하는 한계를 가진다.
3. Refinement Network
Refinement Network는 mask에 Wraping된 의류 $c’$와 $I’$을 이용하여 Encoder-Decoder Network에서 표현하지못한 의상의 디테일 부분을 개선하여 생성하려고 한다.
Wrapped clothing item.
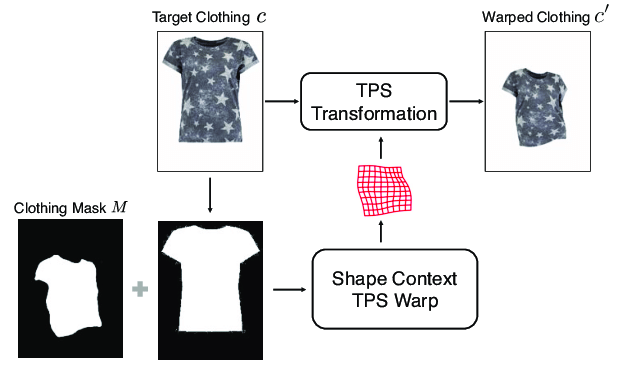 기존의 의류 c를 Network에 그대로 사용하지 못하기 때문에 기존의 의류 c와 clothing Mask M을 이용하여 Thin Plate Spline(TPS) Transformation을 통해 의류 이미지(c)는 디테일을 유지한채로 인물의 포즈 및 체형에 맞는 $c’$으로 변환된다.
기존의 의류 c를 Network에 그대로 사용하지 못하기 때문에 기존의 의류 c와 clothing Mask M을 이용하여 Thin Plate Spline(TPS) Transformation을 통해 의류 이미지(c)는 디테일을 유지한채로 인물의 포즈 및 체형에 맞는 $c’$으로 변환된다.
Learn to composite.
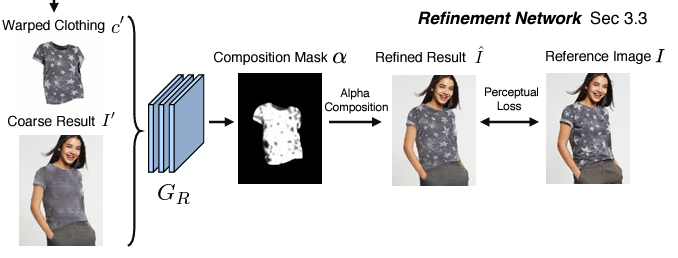
위에서 생성한 $I’$과 $c’$을 Refinement Network $G_R$의 입력으로 넣는다. 여기서 $G_R$은 $c’$의 디테일을 활용하여 디테일이 없거나 배경처럼 덜 중요한 영역은 0(검정색), 디테일이 있는 중요한 영역은 1(흰색)로 채워진 binary composition mask $\alpha$ 를 생성한다. 놀랍게도 지금까지 쓰이지 않았던 Face and hair segment. 정보가 여기서 사용된다. 의류부분과 얼굴,머리카락 부분이 겹치는 경우가 많기 때문에 이를 처리하기 위해 이때 자연스럽게 사용되어 의류 부분만 뽑을 수 있게 된다.
그다음 $\alpha$와 $I’$을 활용하여 합성한 $\hat I$를 만들어준다. 디테일이 있는 부분은 $c’$을 따라가고 디테일이 없는 부분은 $I’$을 따라가게 만든다.
\[\hat I = \alpha \odot c' + (1 - \alpha) \odot I',\]다음으로 원본 이미지 $I$와 synthetic image $\hat I$가 최대한 비슷한 것을 목표로 하는 perceptual loss가 한 번 더 적용이 된다.
\[L_{\text{perc}}(\hat{I}, I) = \sum_{i=3}^{5} \lambda_i \left\| \phi_i(\hat{I}) - \phi_i(I) \right\|_1,\]그럼 마지막으로 Refinement Network가 최종 합성 이미지를 더 사실적으로 보이도록 $G_R$을 최적화 해야한다. 여기서 $L_{G_R}$은 Refinement Network의 총 손실 함수이다. 두번째 항과 세번째 항은 둘 다 규제 항으로 두번째 항은 $L_1$ 규제항으로 마스크 $\alpha$가 높은 정확도로 구분하는 항이고, 세번째 항은 TV(Total Variation) 규제항으로 이미지의 불연속성을 최소화하며 부드러운 이미지를 위해 추가하는 규제항이라고 한다.
결론적으로 음의 $L_1$ 항을 최소화하면 의류 이미지의 디테일 정보를 더 많이 렌더링 할 수 있고, TV 규제항을 최소화하면 더 자연스러운 이미지를 생성할 수 있는 것이다.
\[L_{G_R} = L_{\text{perc}}(\hat{I}, I) - \lambda_{\text{warp}} \left\| \alpha \right\|_1 + \lambda_{\text{TV}} \left\| \nabla \alpha \right\|_1\]
이로써 VITON모델이 완성이 되었고 model에서 step이 진행되면서 얻어지는 결과물들을 통해 점점 자연스럽게 합성되어가는 과정을 확인할 수 있다.
마지막으로 정리를 해보자면 Encoder-Decoder 부분에서 의류와 인물에 대한 정보가 주어지면 디테일들을 제외한 인물의 포즈, 체형, 얼굴이 보존된채로 의류가 합성된 결과물을 생성한다.
이후 Refinement 부분에서 의류를 wraping하고 의류의 디테일 위치의 정보를 담은 Composition Mask가 생성되어 이를 통해 디테일한 부분까지 최종 합성된 이미지가 생성되게 된다.
Experiments
1. Dataset
데이터셋은 크롤링을 통해 16253 쌍의 정면을 바라고있는 여성 이미지와 상의 사진을 이용했다고 한다. 이중 87 ~ 88% 정도를 train, 나머지를 test data로 사용하는데 train 데이터는 인물과 의상이 pair하지만 test data에는 검증을 위해 randomly shuffle 되었다고 한다.
2. Implementation Details
Training setup.
- Adam optimizer: $\beta_1 = 0.5$, $\beta_2 = 0.999$, $lr = 0.0002$
- Encoder-decoder: 15K, Refinement: 6K, batchsize = 16
- synthetic samples size = $256 X 192$
Encoder-decoder generator.
- 6 convolutional layer
- Encoding layer consist 4x4 filter, stride of 2, number of filters 64, 128, 256, 512, 512, 512
- Decoding layer consist 4x4 filter, number of filters 512, 512, 256, 128, 64, 4
Refinement Network
- 4 fully convolutional model.
- 첫 3개 layer는 3 x 3 x 64 filters and Leaky ReLU
- 마지막 layer는 composition mask를 위해 1 x 1 filter와 sigmoid
3. Compared Approaches
4. Qualitative Results
Qualitative comparisons of different methods.
비슷하게 사용될 수 있는 모델들과의 결과물 비교를 해보게 되면 대부분의 모델들이 detail들을 그대로 보존하지 못하고 detail을 보존했을 경우 인물의 pose에 못 따라오는 경우가 대다수이다.
하지만 VITON 모델에서 상의 의상만 바뀌어야 하는데 바지도 같이 바뀌는 경우가 생겨버린다. 이 부분은 Face and hair segment. 때와 같이 바지도 따로 추출해준다면 충분히 보존할 수 있다고 한다.

Person Representation.
다음으로 논문에서 중요한 아이디어로 제시된 person representation의 효과를 살펴보자면 pose 정보만으로 봤을 때는 확실히 인물의 pose는 잘 보존된 채로 결과물이 나오는 것을 확인할 수 있다. 다만 body shape mask image 때문에 의상과 인물이 겹쳐있는 경우 충돌로인한 artifact noise가 생기는 걸 확인할 수 있다.

Failure cases.
이제부터는 모델의 한계점에 가까운데 아래의 왼쪽 예시와 같이 pose가 너무 가려진다거나 복잡할 경우 잘못된 결과물이 나오고 오른쪽과 같이 인물의 체형과 옷의 shape이 크게 맞지 않을 때 artifact가 생기는 것을 확인할 수 있다.

Artifacts near Neck.
또다른 문제로는 의류 이미지에서 neck 내부 모습이 들어가 있는 경우 표현되지 말아야 하는 부분이 표현되어 버리는 문제가 생긴다. 이를 해결하기 위해 neck 내부 모습을 제거해주면 해결 되는 것을 확인할 수 있다.

5. Quantitative Results
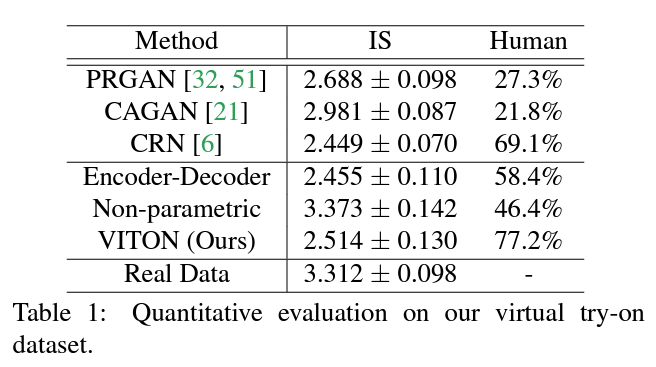
Inception Score는 이미지 생성 모델의 합성 퀄리티를 평가하는 지표로 퀄리티가 높을 수록 높은 점수를 부여 받게 된다. 다만 지금까지 사용했던 Inception Score가 Virtual Try-on의 평가지표로 사용하기에는 적합하지 않다는 결론을 내리게 되었다고 한다.
그렇게 Human evaluation metric을 따르기로 결정했고 해당 지표로 봤을 때 다른 생성형 모델보다 월등히 성능이 높은 것을 확인할 수 있었다.
Conclusion
결론적으로 전체적으로 비용이 비싼 3D 기반 method대신 2D RGB Image를 이용한 실용적으로 사용될 수 있는 model을 만들었다고 한다.
Reference.
https://arxiv.org/abs/1711.08447
https://github.com/xthan/VITON
Enjoy Reading This Article?
Here are some more articles you might like to read next: